PHP知道与问问的采集插件代码,可以使用正则表达式和cURL库进行数据抓取和处理。 PHP是一种广泛使用的开源服务器端脚本语言,特别适用于Web开发,在构建基于PHP和MySQL的动态网站时,采集插件代码可以帮助从百度知……
在WPS中,可以通过“数据”菜单选择“从网页导入数据”功能,按提示操作即可。 在当今信息时代,网页数据的有效利用对于数据分析、报告制作等方面至关重要,WPS作为一款功能强大的办公软件,提供了多种方法将网页数据……
以下是一个使用Snoopy进行PHP采集的简单示例:,``php,,``,在这段代码中,首先引入了Snoopy类,然后创建了一个Snoopy对象。调用fetch方法获取指定URL的内容。通过getHTML方法获取并打印网页的HTML内容。 Snoopy……
大数据采集工具是用于从各种来源提取、收集和处理大量数据的软件和技术,这些工具可以帮助企业和个人更有效地收集和分析数据,从而为决策提供有力支持,以下是一些常用的大数据采集工具: (图片来源网络,侵删……
Fiddler是一个用于调试网络请求的工具,它可以捕获、分析和修改HTTP、HTTPS等协议的请求和响应,Fiddler主要用于Web开发和测试,帮助开发者诊断和解决网络相关的问题,以下是Fiddler的一些主要功能: (图片来源……
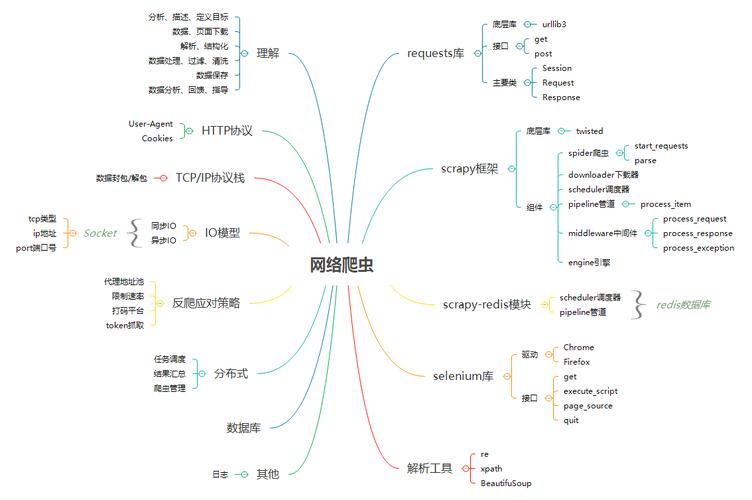
Python爬虫分类主要可以分为以下几类: (图片来源网络,侵删) 1、基于requests库的爬虫 使用requests库发送HTTP请求,获取网页内容 使用BeautifulSoup库解析网页内容,提取所需数据 2、基于selenium库……
网络数据抓取 爬虫技术,也称为网络蜘蛛或网络爬虫,是自动访问网页并收集其信息的一种技术,最直观的应用就是网络数据的抓取,比如新闻聚合网站会使用爬虫技术从各个新闻网站抓取最新的新闻内容,搜索引擎也会使……
搭建蜘蛛池,通常是指在服务器上创建一个网络爬虫(俗称“蜘蛛”)的集群环境,用于执行大规模的数据爬取任务,选择香港的IP地址来搭建这样的服务器有其独特的好处,主要基于以下几点: (图片来源网络,侵删) 1……
要读取HTML表格单元格,可以使用Python的BeautifulSoup库进行解析。首先安装库,然后使用以下代码:,,``python,from bs4 import BeautifulSoup,import requests,,url = '你的网址',response = requests.get……
了解并掌握适用于不同需求的爬虫工具,对于进行大数据精准获客是至关重要的。 (图片来源网络,侵删) 在当今信息时代,获取和分析海量数据对于企业而言变得越来越重要。通过使用合适的爬虫工具,我们可以自动……