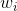方法出自Google文章Detecting Near-Duplicates for Web Crawling(2007 WWW)。 Google要解决的问题是当crawler得到一个网页时,如何判断该网页是否是已经存在的或存在相似的。 解决这个问题分……