1.什么是RDD?
什么是RDD?
RDD(Resilient Distributed Dataset)叫做弹性分布式数据集,是Spark中最基本的数据抽象,它代表一个不可变、可分区、弹性。RDD是一个可以并行操作的容错的容错集合集合。
1.不可以变是指的是对rdd进行算子计算,会生成一个新的rdd,不会改变原来最初的rdd.
2.数据可以分区处理
3.把数据进行分区,把数据分区完了之后可以分别发给exector进行执行。实现并行。
RDD的属性(源码中的一段话)
1.一组分片(Partition),对于RDD来说,每个分片都会被一个计算任务处理。用户没有指定分片数按找cpu的core数目来指定。
2.一个计算每个分区的函数。Spark中RDD的计算是以分片为单位的。
3.RDD之间的依赖关系。RDD的每次转换都会生成一个新的RDD,所以RDD之间就会形成类似于流水线一样的前后依赖关系。数据丢失也不要重复计算。(血统linear)
4.一个Partitioner,即RDD的分片函数。当前Spark中实现了两种类型的分片函数,一个是基于哈希的HashPartitioner,另外一个是基于范围的RangePartitioner。
5.一个列表,存储存取每个Partition的优先位置(preferred location)移动计算。
RDD的特点?
RDD表示只读的分区数据集,对RDD改动,只能通过转换操作,RDDs之间存在依赖,这种依赖是称为血缘,如果血缘比较长,可以通过持久化RDD来切断血缘关系。
算子?
就是从一个状态转换到另外一个状态,spark中所有RDD方法称为算子,分为两大类:转换算子和行动算子。
依赖?
RDDs的转换关系形成依赖关系,依赖关系分为两种,一种是宽依赖,一种是窄依赖。
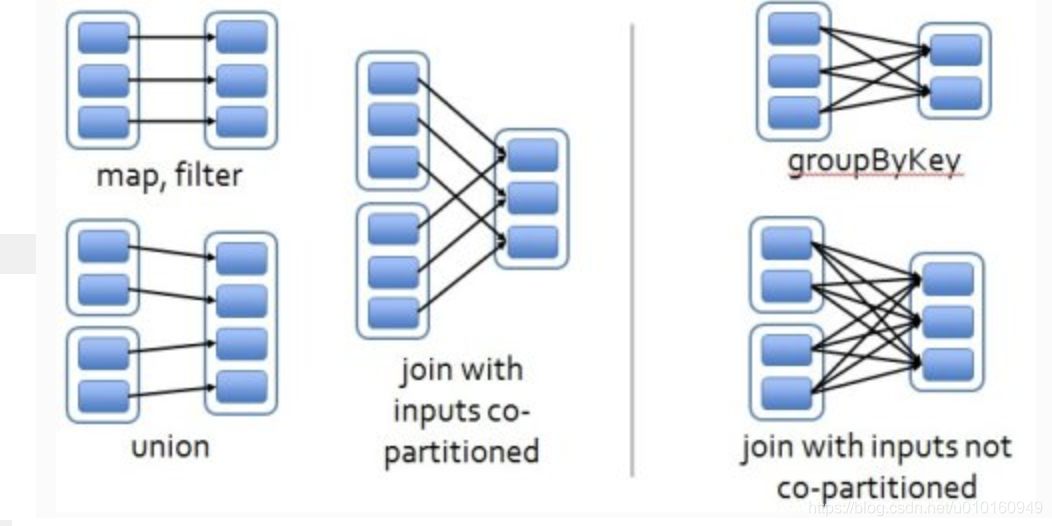
窄依赖是指每个父RDD的Partition最多被子RDD的一个Partition所使用,例如map、filter,见上左图
宽依赖是指一个父RDD的Partition会被多个子RDD的Partition所使用,例如groupByKey、reduceByKey等
RDD缓存?
把数据缓存下来进行保存。缓存每个RDD
RDD的创建?
11.通过外部的数据文件创建,如HDFS
val rdd1 = sc.textFile(“hdfs://192.168.88.111:9000/data/data.txt”)
2.通过sc.parallelize进行创建–并行化,默认分区是按照核数。
val rdd1 = sc.parallelize(Array(1,2,3,4,5,6,7,8))
val redd2=sc.makeRDD(Array(1,2,3,4,5,6,6,7,8))
3.从其他集合转换。
RDD的类型:Transformation和Action
Rdd 的转换算子?
value类型和key-value类型
1.value类型—map算子
作用:返回一个新的RDD,该RDD由每个输入元素经过func函数转换后组成
//1.创建–创建一个rdd
val listRdd=sc.makeRDD(Array(1,2,3,4,5,6))
//2.对RDD的每个元素进行操作
val mapRdd=listRdd.map(x=>x2);
//3.对集合转成集合,输出
mapRdd.collect().foreach(println)
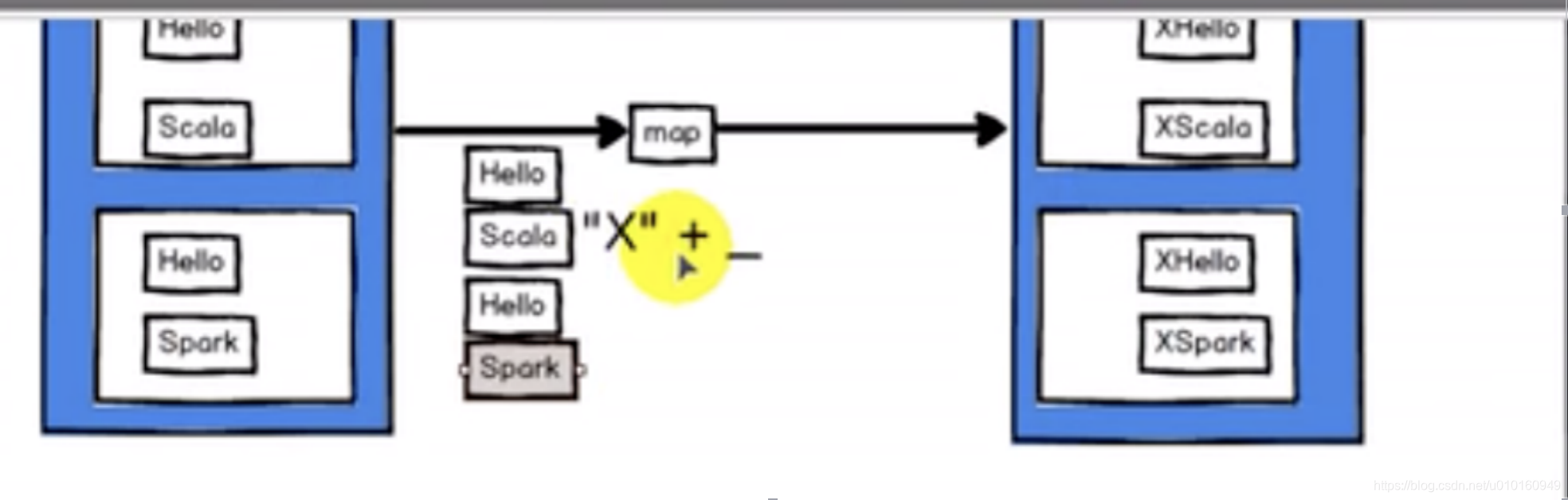
总结把数据一个个取出来进行处理。
2.mappartitioner–把分区数据当成一个整体来处理,func函数类型必须是Iterator[T]=>Iterator[U]。只会调用分区个数次数,不是一个个元素处理
//1.创建–创建一个rdd
val listRdd=sc.makeRDD(Array(1,2,3,4,5,6))
//2.对RDD的每个元素进行操作
val mapRdd=listRdd.mapPartitions(datas=>{
//datas是每个分区集合。map对集合每个元素进行2
datas.map(data=>data*2)
});
//3.对集合转成集合,输出
mapRdd.collect().foreach(println)
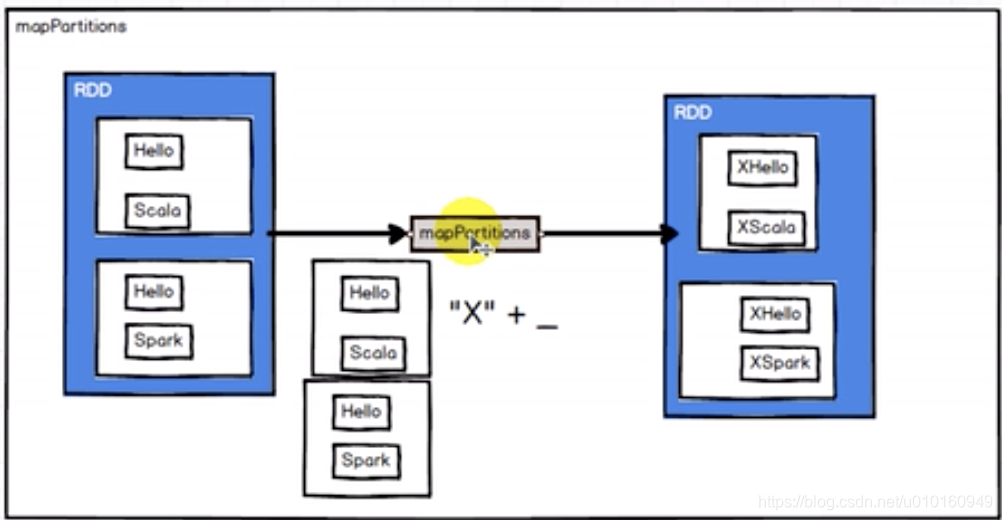
1.效率是执行高,整体发给executor。
2.mappatititions发exector
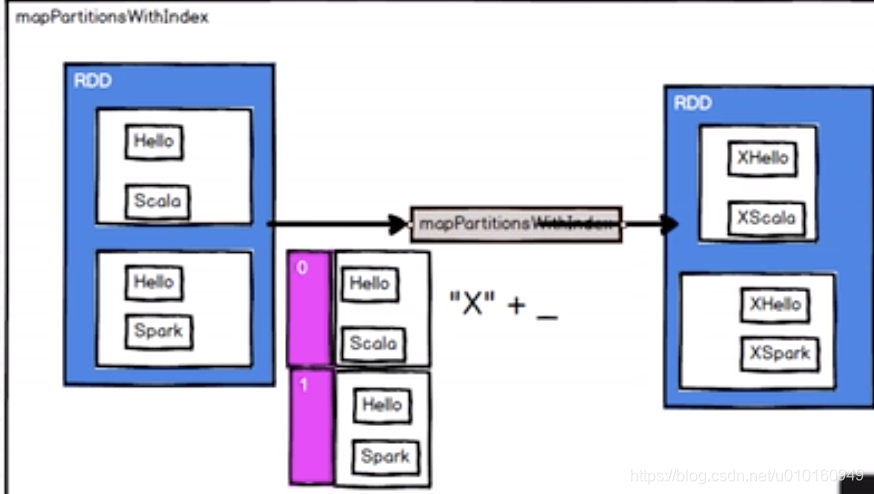
mapPartitionsWithIndex(func)–关系分区号,关心那些数据放在那个分区。
但func带有一个整数参数表示分片的索引值,因此在类型为T的RDD上运行时,func的函数类型必须是(Int, Interator[T]) => Iterator[U])
//1.创建–创建一个rdd
val listRdd=sc.makeRDD(Array(1,2,3,4,5,6),2)
//2.对RDD的每个元素进行操作
val mapRdd=listRdd.mapPartitionsWithIndex(
case(num,datas)=>{
//每个元素
datas.map((_,“分区号”+num))
}
})
//3.对集合转成集合,输出
mapRdd.collect().foreach(println)
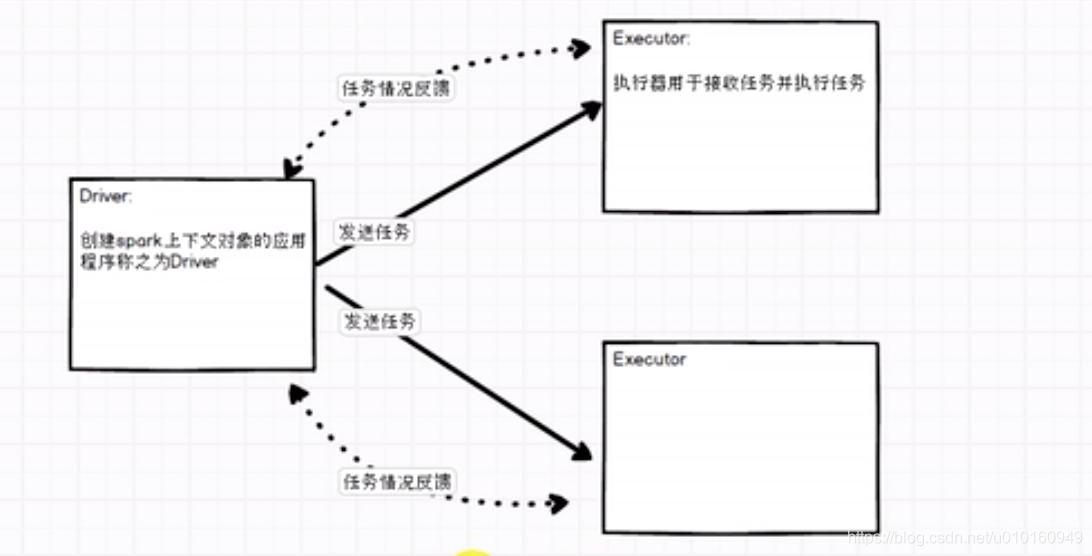
driver与executor 关系–所有的计算都是在executor执行的
flatMap–把一个个整体拆成一个个个体。
每一个输入元素可以被映射为0或多个输出元素(所以func应该返回一个序列,而不是单一元素)
//1.创建–创建一个rdd
val listRdd=sc.makeRDD(Array(List(1,2),List(3,4)))
//2.对RDD的每个元素进行操作
val mapRdd=listRdd.flatMap(datas=>datas)
//3.对集合转成集合,输出
mapRdd.collect().foreach(println)
map与mapartition的区别?
1.map:每次处理一条数据
2.mappartition:每次处理一个分区的数据,处理完了才能释放资源。内存大建议。
glom-把分区的数据存到一个数组中。
//1.创建–创建一个rdd
val listRdd=sc.makeRDD(List(1,2),2)
//2.对RDD的每个元素进行操作
val mapRdd=listRdd.glom()
mapRdd.collect().foreach(array=>{
println(array.mkstring(","))
})
group by–分组
按照传入函数的返回值进行分组。按相同key是一组。
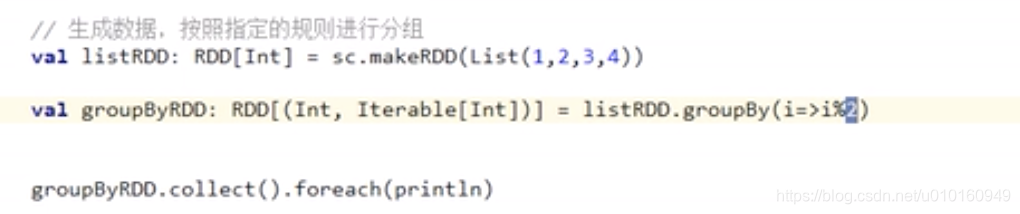
形成了key -value ,key是分组的key,v是分组的数据集合。
sample(withReplacement, fraction, seed)–采样
根据fraction指定的比例对数据进行采样,withReplacement表示抽的数据是否放回,true是否返回,false无放回,seed用于指定随机生成器种子。
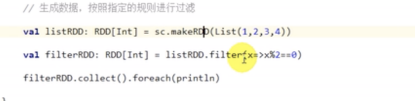
filter–过滤,返回一个新的rdd,Rdd经过func函数计算后返回值为true的元素组成
distinct–对RDD去重返回一个新的RDD,去除重复的最后一个
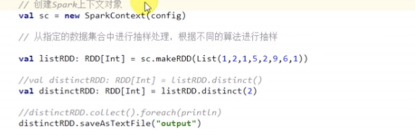
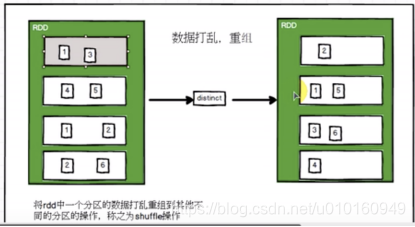
distinct(2)–代表两个分区保存去重复的数据。会造成shuffle
coalesce—缩小分区数。