Linux下Hadoop安装与配置
- 一、安装JDK
- 二、安装Hadoop
-
- 1. Hadoop下载解压
- 2.环境配置
- 3.配置Hadoop
- 4.启动Hadoop
一、安装JDK
自己安装
二、安装Hadoop
1. Hadoop下载解压
wget https://archive.apache.org/dist/hadoop/common/hadoop-3.3.1/hadoop-3.3.1.tar.gz
tar -zxvf hadoop-3.3.1.tar.gz
2.环境配置
vim /etc/profile
在文件最下方加入以下配置
export JAVA_HOME=/opt/jdk1.8.0_301
export HADOOP_HOME=/opt/hadoop
export PATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
export JRE_HOME=$JAVA_HOME/jre
使环境变量生效
source /etc/profile

3.配置Hadoop
修改主机名
vim /etc/sysconfig/network
在下方加入 HOSTNAME=hadoop1
不生效 使用 命令行 hostname hadoop1 临时修改
查看主机名:
hostname
修改Hadoop的配置文件
修改core-site.xml 文件
vim /opt/hadoop-3.3.1/etc/hadoop/core-site.xml
<configuration><property><name>hadoop.tmp.dir</name><value>/hadoop</value></property><property><name>dfs.name.dir</name><value>/hadoop/name</value></property><property><name>fs.default.name</name><value>hdfs://hadoop1:9000</value></property>
</configuration>
修改hdfs-site.xml 文件
vim /opt/hadoop-3.3.1/etc/hadoop/hdfs-site.xml
<configuration><property><name>dfs.data.dir</name><value>/hadoop/data</value></property><property><name>dfs.replication</name><value>1</value></property><property><name>dfs.permissions</name><value>false</value></property><property><name>dfs.client.use.datanode.hostname</name><value>true</value><description>only cofig in clients</description></property>
</configuration>
修改 hadoop-env.sh 文件
vim /opt/hadoop-3.3.1/etc/hadoop/hadoop-env.sh
在下方加入一行
export JAVA_HOME=/opt/jdk1.8.0_301
修改 mapred-site.xml 文件
vim /opt/hadoop-3.3.1/etc/hadoop/mapred-site.xml
<configuration><property><name>mapred.job.tracker</name><value>september:9001</value></property><property><name>mapred.local.dir</name><value>/hadoop/logs</value></property></configuration>
修改 sbin目录下的 start-dfs.sh 和 stop-dfs.sh 文件
vim /opt/hadoop-3.3.1/sbin/start-dfs.sh
vim /opt/hadoop-3.3.1/sbin/stop-dfs.sh
HDFS_DATANODE_USER=root
HDFS_DATANODE_SECURE_USER=hdfs
HDFS_NAMENODE_USER=root
HDFS_SECONDARYNAMENODE_USER=root
修改 sbin目录下的 start-yarn.sh 和 stop-yarn.sh 文件
vim /opt/hadoop-3.3.1/sbin/start-yarn.sh
vim /opt/hadoop-3.3.1/sbin/stop-yarn.sh
YARN_RESOURCEMANAGER_USER=root
HADOOP_SECURE_DN_USER=yarn
YARN_NODEMANAGER_USER=root
配置算是修改完了, 再配置一个ssh免密登录
ssh-keygen -t rsa
一路回车
ssh-copy-id -i /root/.ssh/id_dsa.pub root@ *.*.*.* //这里是IP地址
4.启动Hadoop
hadoop namenode -format
start-all.sh
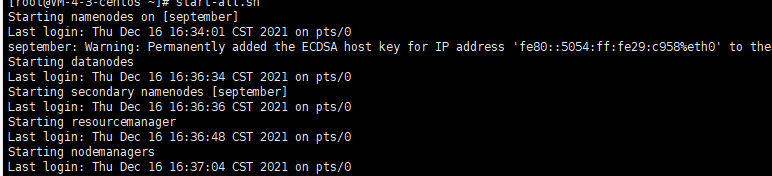
启动完了用jps命令看一下
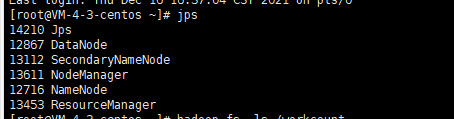
启动就完事了