# -*- coding: utf-8 -*-##-------------------------------------------------------------------------------
# Name: 参数优化
# Description:
# Author: shichao, 联系方式: 961771865
# Date: 2019/2/7
#-------------------------------------------------------------------------------import os
import numpy as np
import pandas as pd
import time
from sklearn.multioutput import MultiOutputRegressor
import matplotlib.pyplot as plt# 核心代码,设置显示的最大列、宽等参数,消掉打印不完全中间的省略号
pd.set_option('display.max_columns', 1000)
pd.set_option('display.width', 1000)
pd.set_option('display.max_colwidth', 1000)# 设置交叉验证集的折数
from sklearn.model_selection import cross_val_score
# 时间序列分割
from sklearn.model_selection import TimeSeriesSplit
tscv = TimeSeriesSplit(max_train_size=None, n_splits=13)
def cv_mae(model, train_X, train_y):mae= np.mean(-cross_val_score(model, train_X, train_y, scoring="neg_mean_absolute_error", cv = tscv))return(mae)# 画图:参数与交叉验证集上的折线图
def parameter_plot(x_list, y_list, x_title, y_title, plot_name):# 参数优化折线图#plt.figure(1, figsize=(26, 13))plt.plot(x_list, y_list, marker='o')plt.xlabel(x_title)plt.ylabel(y_title)plt.title(plot_name)plt.show()# 参数优化: GBDT
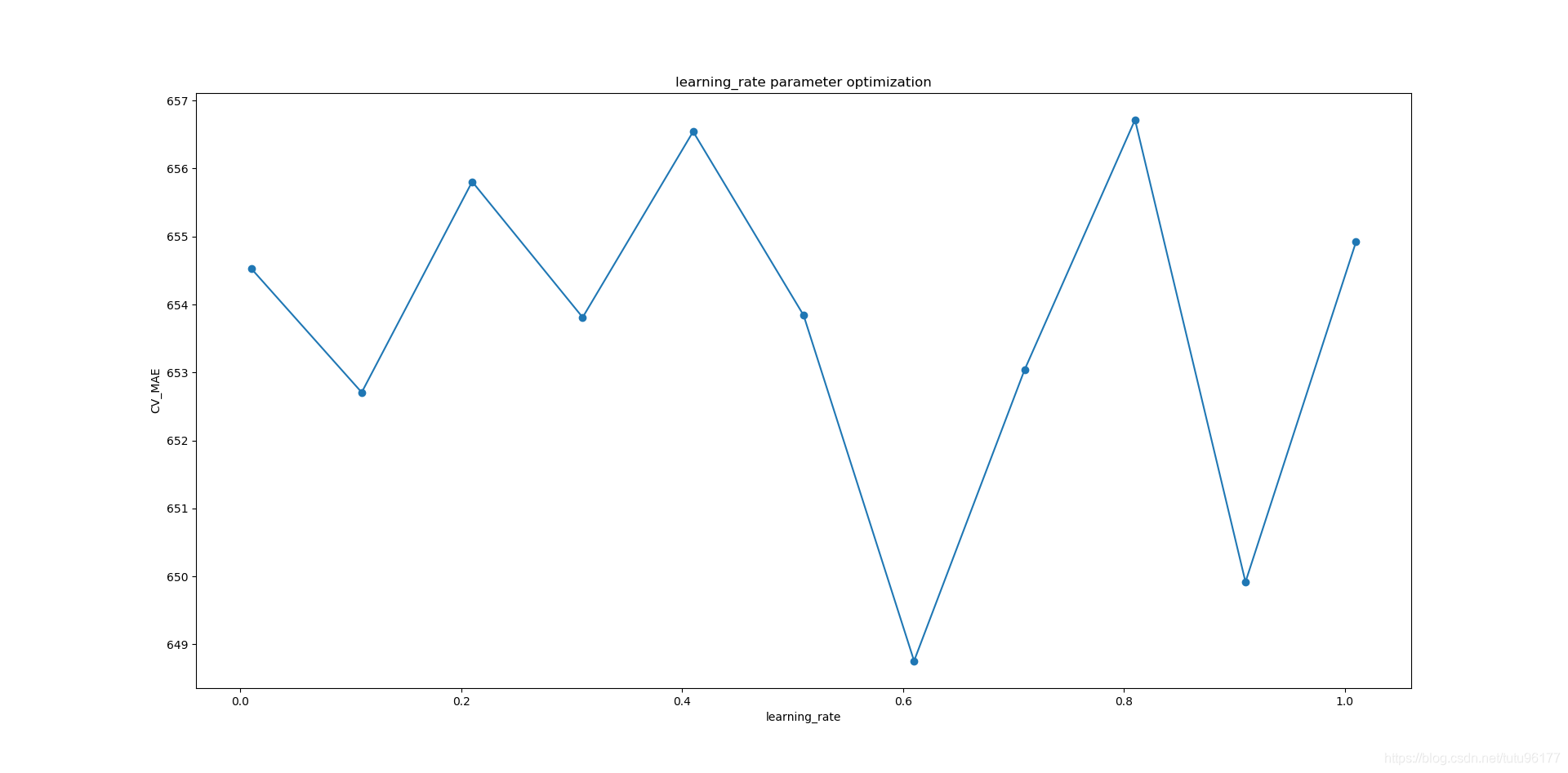
def parameter_optimize(train_X, train_y):from sklearn.ensemble import GradientBoostingRegressor# 回归树的颗数cv_mae_list = []n_estimator_list = []# 暴力搜索,选取最优参数 n_estimators : 295# parameter_name = 'n_estimators'# n_estimators = [x for x in range(20, 310, 5)]# for n_estimator in n_estimators:# boost_initialize_params = {'n_estimators': n_estimator, 'learning_rate': 0.1, 'subsample': 1.0, 'loss': 'ls'}# base_initialize_params = {'max_depth': 3, 'min_samples_split': 2, 'alpha': 0.9, 'random_state': 42}# initialize_params = {}# initialize_params.update(boost_initialize_params)# initialize_params.update(base_initialize_params)# model = GradientBoostingRegressor()# mult_model = MultiOutputRegressor(model)# cv_mae_model = cv_mae(mult_model, train_X, train_y)# cv_mae_list.append(cv_mae_model)# n_estimator_list.append(n_estimator)# print ('{0} :{1} , 交叉验证平均绝对误差:{2}'.format((parameter_name),(n_estimator),(cv_mae_model)))# parameter_plot(n_estimator_list, cv_mae_list, 'n_estimators', 'CV_MAE', 'n_estimators parameter optimization')# 暴力搜索:选取最优参数 learning_rate : 0.61# n_learning_rate = list(np.arange(0.01, 1.1, 0.1))# parameter_name = 'learning_rate'# for n_estimator in n_learning_rate:# boost_initialize_params = {'n_estimators': 295, 'learning_rate': n_estimator, 'subsample': 1.0, 'loss': 'ls'}# base_initialize_params = {'max_depth': 3, 'min_samples_split': 2, 'alpha': 0.9, 'random_state': 42}# initialize_params = {}# initialize_params.update(boost_initialize_params)# initialize_params.update(base_initialize_params)# model = GradientBoostingRegressor()# mult_model = MultiOutputRegressor(model)# cv_mae_model = cv_mae(mult_model, train_X, train_y)# cv_mae_list.append(cv_mae_model)# n_estimator_list.append(n_estimator)# print('{0} :{1} , 交叉验证平均绝对误差:{2}'.format((parameter_name), (n_estimator), (cv_mae_model)))# parameter_plot(n_estimator_list, cv_mae_list, parameter_name, 'CV_MAE', parameter_name + ' parameter optimization')# # 暴力搜索:选取最优参数 subsample : 0.1# subsample = list(np.arange(0, 1.1, 0.1))# parameter_name = 'subsample'# for n_estimator in subsample:# boost_initialize_params = {'n_estimators': 295, 'learning_rate': 0.61, 'subsample': n_estimator, 'loss': 'ls'}# base_initialize_params = {'max_depth': 3, 'min_samples_split': 2, 'alpha': 0.9, 'random_state': 42}# initialize_params = {}# initialize_params.update(boost_initialize_params)# initialize_params.update(base_initialize_params)# model = GradientBoostingRegressor()# mult_model = MultiOutputRegressor(model)# cv_mae_model = cv_mae(mult_model, train_X, train_y)# cv_mae_list.append(cv_mae_model)# n_estimator_list.append(n_estimator)# print('{0} :{1} , 交叉验证平均绝对误差:{2}'.format((parameter_name), (n_estimator), (cv_mae_model)))# parameter_plot(n_estimator_list, cv_mae_list, parameter_name, 'CV_MAE', parameter_name + ' parameter optimization')# 暴力搜索:选取最优参数 loss : 'quantile'# loss = ['ls', 'lad', 'huber', 'quantile']# parameter_name = 'loss'# for n_estimator in loss:# boost_initialize_params = {'n_estimators': 295, 'learning_rate': 0.61, 'subsample': 0.1, 'loss': n_estimator}# base_initialize_params = {'max_depth': 3, 'min_samples_split': 2, 'alpha': 0.9, 'random_state': 42}# initialize_params = {}# initialize_params.update(boost_initialize_params)# initialize_params.update(base_initialize_params)# model = GradientBoostingRegressor()# mult_model = MultiOutputRegressor(model)# cv_mae_model = cv_mae(mult_model, train_X, train_y)# cv_mae_list.append(cv_mae_model)# n_estimator_list.append(n_estimator)# print('{0} :{1} , 交叉验证平均绝对误差:{2}'.format((parameter_name), (n_estimator), (cv_mae_model)))# parameter_plot(n_estimator_list, cv_mae_list, parameter_name, 'CV_MAE', parameter_name + ' parameter optimization')# 暴力搜索:选取最优参数 max_depth : 6# parameter_name = 'max_depth'# max_depth = list(np.arange(1, 40, 1))# for n_estimator in max_depth:# boost_initialize_params = {'n_estimators': 295, 'learning_rate': 0.61, 'subsample': 1.0, 'loss': 'quantile'}# base_initialize_params = {'max_depth': 3, 'min_samples_split': 2, 'alpha': 0.9, 'random_state': 42}# initialize_params = {}# initialize_params.update(boost_initialize_params)# initialize_params.update(base_initialize_params)# model = GradientBoostingRegressor()# mult_model = MultiOutputRegressor(model)# cv_mae_model = cv_mae(mult_model, train_X, train_y)# cv_mae_list.append(cv_mae_model)# n_estimator_list.append(n_estimator)# print('{0} :{1} , 交叉验证平均绝对误差:{2}'.format((parameter_name), (n_estimator), (cv_mae_model)))# parameter_plot(n_estimator_list, cv_mae_list, parameter_name, 'CV_MAE', parameter_name + ' parameter optimization')# 暴力搜索:选取最优参数 min_samples_split : 0.51# parameter_name = 'min_samples_split'# min_samples_split = list(np.arange(0.01, 3, 0.1))# for n_estimator in min_samples_split:# boost_initialize_params = {'n_estimators': 295, 'learning_rate': 0.61, 'subsample': 1.0, 'loss': 'quantile'}# base_initialize_params = {'max_depth': 6, 'min_samples_split': n_estimator, 'alpha': 0.9, 'random_state': 42}# initialize_params = {}# initialize_params.update(boost_initialize_params)# initialize_params.update(base_initialize_params)# model = GradientBoostingRegressor()# mult_model = MultiOutputRegressor(model)# cv_mae_model = cv_mae(mult_model, train_X, train_y)# cv_mae_list.append(cv_mae_model)# n_estimator_list.append(n_estimator)# print('{0} :{1} , 交叉验证平均绝对误差:{2}'.format((parameter_name), (n_estimator), (cv_mae_model)))# parameter_plot(n_estimator_list, cv_mae_list, parameter_name, 'CV_MAE', parameter_name + ' parameter optimization')#暴力搜索:选取最优参数 alpha: 0.11parameter_name = 'alpha'alpha = list(np.arange(0.01, 1, 0.1))for n_estimator in alpha:boost_initialize_params = {'n_estimators': 295, 'learning_rate': 0.61, 'subsample': 1.0, 'loss': 'quantile'}base_initialize_params = {'max_depth': 6, 'min_samples_split': 0.51, 'alpha': n_estimator, 'random_state': 42}initialize_params = {}initialize_params.update(boost_initialize_params)initialize_params.update(base_initialize_params)model = GradientBoostingRegressor()mult_model = MultiOutputRegressor(model)cv_mae_model = cv_mae(mult_model, train_X, train_y)cv_mae_list.append(cv_mae_model)n_estimator_list.append(n_estimator)print('{0} :{1} , 交叉验证平均绝对误差:{2}'.format((parameter_name), (n_estimator), (cv_mae_model)))parameter_plot(n_estimator_list, cv_mae_list, parameter_name, 'CV_MAE', parameter_name + ' parameter optimization')print ()
下图是对学习率的选择过程,交叉验证平均绝对误差最小,对应的就是最优学习率。