数据
数据集是kaggle上关于steam游戏的数据,链接在此
数据解释:
- name: 游戏名称
- average_2weeks: 最近两周不知啥的平均值数据集上也没有写
- average_foreve: 同上
- owners: 多少人把游戏加入游戏库
- players_foreve: 多少人玩过游戏
- negative: 不喜欢人数
- positive: 喜欢人数
- price: 价格(美分)
- publisher: 发布者/厂商
- score_rank: 评分情况
- userscore: 玩家打分
数据预处理
import pandas as pd
import matplotlib.pyplot as plt
import numpy as np
import seaborn as sns
from sqlalchemy import create_engine
import warnings
import sqlite3
import matplotlib.cm as cm
warnings.filterwarnings('ignore')
# 设置风格
%matplotlib inline
plt.style.use('ggplot')
np.random.seed(2018)# 链接数据库
engine = create_engine('sqlite:home/ffzs/data_analysis/visualization/seaborn/steam.sqlite')# 导入数据
cols = ['name','average_2weeks', 'average_forever', 'owners', 'players_forever','negative', 'positive', 'price', 'publisher', 'score_rank', 'userscore']
df = pd.read_sql('select * from SteamSpy', con=engine)[cols]
df.head(2).T
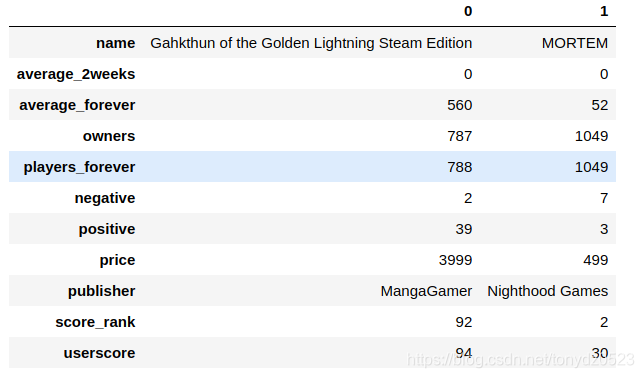
缺失值查询:
df.isna().sum()
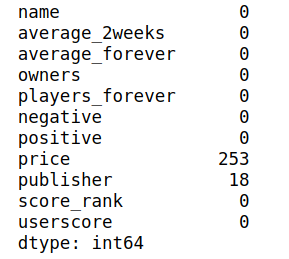
发现数据有空值和空格值:
# 将数据中的' '(空格) 转换为 ''
df = df.applymap(lambda x : x.strip() if isinstance(x, str) else x)# 查看空值情况
(df=='').sum()
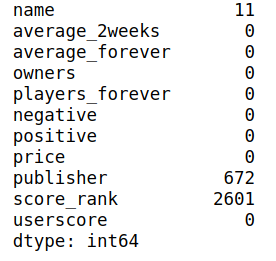
游戏名称的空值直接删除,price缺失值比较多,暂且用0代替,发布者的缺失值和空值都换成"-",score_rank空值用0替换
处理缺失值和空值:
# 删除name为空的行
df.drop(df[df.name==''].index, axis=0, inplace=True)# 处理price缺失值
df.fillna(value={'price':0, 'publisher':'-'}, inplace=True)
# 数据类型转化为int
df.price = df.price.astype('int')# score_rank 空白值转化成 0
df.replace({'score_rank':''},{'score_rank':0}, inplace=True)
# 更改数据类型
df.score_rank = df.score_rank.astype('int')
# publisher 空白值转化为 -
df.replace({'publisher':''},{'publisher':'-'}, inplace=True)
处理name列重复情况:
# name重名情况处理
df.name.value_counts()[df.name.value_counts()>1].count()
#>>74# 可以查看一下
df[df.duplicated(['name'], keep=False)].sort_values('name', ascending=False)
共74个游戏重名情况,可能是游戏版本更新造成的,这里我们将游戏名重复的游戏留下一个游戏玩家最多的情况
# 根据玩家数排序
df.sort_values('owners', inplace=True)
# 丢掉其他重复数据
df.drop_duplicates(['name'], keep='last', inplace=True)
数据离散化:
# 根据玩家评