c++ 学习笔记 内存模型的基础知识
- 引用cppreference.com中对内存位置的定义:
- 标量对象(算术类型、指针类型、枚举类型或
std::nullptr_t), - 或非零长度的连续序列。
- 标量对象(算术类型、指针类型、枚举类型或
下面是内存位置的例子:
struct S {char a; // memory location #1int b : 5; // memory location #2int c : 11, // memory location #2 (continued): 0,d : 8; // memory location #3int e; // memory location #4double f; // memory location #5std::string g; // several memory locations
};
首先,对象obj由七个子对象组成,其中b、c两个位字段共享内存位置。
观察上述结构体定义,可以得到如下结论:
- 每个变量都是一个对象。
- 标量类型占用一个内存位置。
- 相邻的位字段(b和c)具有相同的内存位置。
- 变量至少占用一个内存位置。
如果两个线程访问相同的内存位置(相邻位字段共享内存位置),并且至少有一个线程想要修改它,那么程序就会产生数据竞争,除非:
- 修改操作为原子操作。
- 访问按照某种先行(happens-before)顺序进行。
第二种情况非常有趣,同步语义(如互斥锁)可以建立了先行关系。这些先行关系基于原子建立,当然也适用于非原子操作。内存序(memory-ordering)是内存模型的关键部分,其定义了先行关系的细节。
编程协议
协议约定的双方为:开发者和系统。系统由生成机器码的编译器、执行机器码的处理器和存储程序状态的缓存组成。每个部分可以进行优化,例如:编译器可以使用寄存器或修改循环,处理器可以乱序执行或分支预测,缓存指令可以预取或缓冲。生成的(在好的情况下)可执行文件,可以针对硬件平台进行了优化。确切地说,这里不只有一个协议,而是一组(细粒度的)协议。换句话说:遵循越弱的规则,程序的优化潜力越大。
有一个经验法则是:协议越强,优化的空间越少。当程序开发者使用弱协议或弱内存模型时,相应就会有许多优化选择。结果是,这个项目只能由少数专家来维护,而你我可能都不属于专家的范畴。
粗略地说,C++11中有三个协议级别。
C++11之前,C++不包括多线程或原子。系统只遵循控制流,因此优化的潜力非常有限。该系统的关键是,保证程序开发者所观察到的程序行为,与源代码中指令的顺序一致。当然,这就意味着没有内存模型,只有序列点。序列点是程序中的点,在这些点上的所有指令的效果是可见的,函数执行的开始或结束都是序列点。当使用两个参数调用一个函数时,C++并不保证先计算哪个参数,因此其行为是未指定的,原因很简单——逗号操作符不是序列点。
C++11中,这些都发生了变化。C++11是C++第一个支持多线程的标准。C++内存模型深受Java内存模型的影响,不过C++内存模型做了很多改进。为了得到定义良好的程序,程序开发者在处理共享变量时必须遵守规则。如果存在数据竞争,则程序的行为是未定义的。如前所述,如果线程共享可变数据,必须注意数据竞争。
在使用原子操作的时候,经常会讨论无锁编程。我在本节中谈到了弱规则和强规则,其中原子操作的顺序一致语义被称为强内存模型,原子操作的自由语义被称为弱内存模型。
基础
C++内存模型需要保证以下操作:
- 原子操作:不受中断地执行。
- 部分排序操作:操作序列的顺序不能重排。
- 可见操作:保证共享变量上的操作对其他线程可见。
协议基础是针对原子操作的,其特点是原子的、不可分割的,并且在执行上会创建同步和约束顺序。当然,同步和约束顺序也适用于非原子的操作。一方面,原子类型上的操作总是原子的;另一方面,可以根据需要定制同步和约束顺序。
内存模型越弱,就能把越多的注意力转放到其他事情上,比如:
- 优化潜力。
- 控制流数量。
- 了解更多底层的知识。
- 程序行为与我们的预期是否一致。
- 更加微观的优化。
原子操作
顺序一致语义是强内存模型,自由语义是弱内存模型。
顺序一致有两个特点:
- 指令按源码顺序执行。
- 线程上的所有操作都遵循一个全局顺序。
下面图形显示了两个线程。每个线程分别将值存储到变量x或y中,获取另一个变量y或x,并存储在变量res1或res2中。
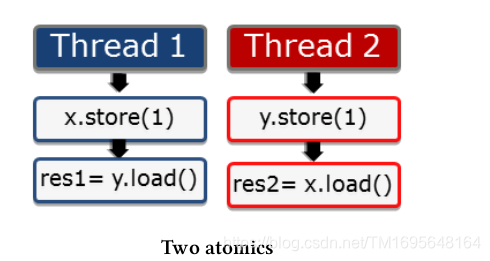
顺序一致性
1:指令按照源码中的顺序执行。任何存储操作都无法在获取操作之前进行。
2:所有线程的指令必须遵循全局顺序。
线程2看到线程1的操作的顺序与线程1执行它们的顺序相同。线程2按照线程1的源码顺序查看线程1的所有操作,从线程1的角度来看也是如此。可以将这个特性,想象成一个所有线程都必须遵循的全局时钟(全局时钟就是全局顺序)。时钟每发出一次滴答声,就会发生一个原子操作,但永远不知道执行的是哪个。
两个线程有以下六种交替运行的方式。
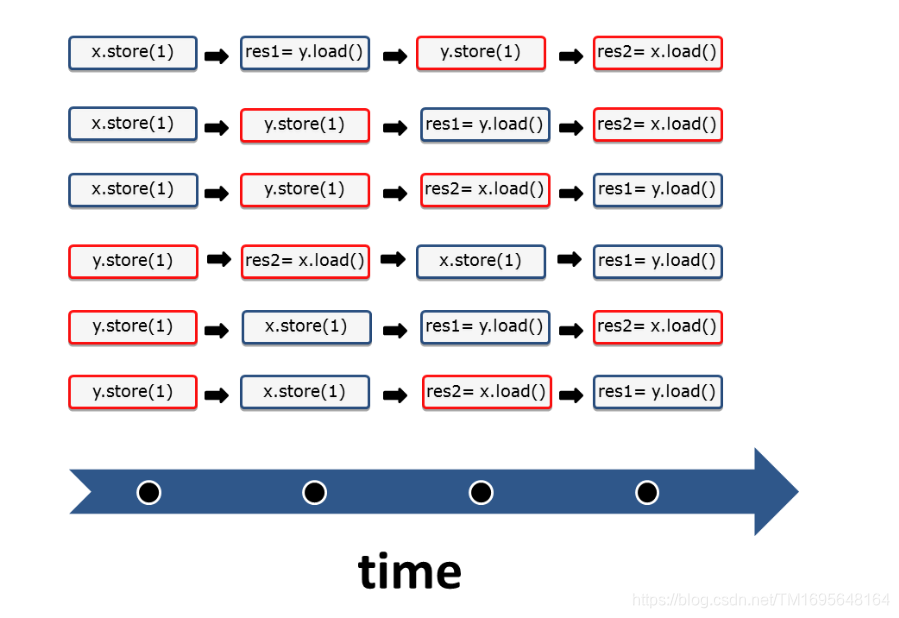
这就是顺序一致语义,也称为强内存模型
弱内存模型
继续看上面的例子:
1.开发者使用了原子操作(开发者遵循协议)。系统保证了程序的行为,从而不会存在数据竞争。
2.使用自由语义(也称为弱内存模型),可使这四种操作有更多的组合。线程1可以以不同的顺序查看线程2的操作,这样全局顺序就不存在了。从线程1的角度来看,操作res2= x.load()可能在y.store(1)之前执行。甚至是,线程1或线程2没有按照源代码中的顺序执行。例如,线程2可以先执行res2= x.load(),再执行y.store(1)。
“序列一致语义”和“自由语义”之间还有存在其他内存模型,其中最重要的是“获取-释放语义“。“获取-释放语义”中,开发人员需要遵守比“顺序一致语义”弱的规则。这样,系统有了更多优化空间。因为线程在特定同步点上进行同步,所以“获取-释放语义“是理解多线程编程中,同步和部分排序的关键。没有同步点,就不可能有(定义良好的)线程、任务或条件变量。
原子操作的默认行为——顺序一致(为每个原子操作指定内存顺序)。如果没有指定内存顺序,则应用保持顺序一致,这意味着std::memory_order_seq_cst将默认应用于每个原子操作。
下面两端段代码是等价的:
x.store(1);
res = x.load();
x.store(1, std::memory_order_seq_cst);
res = x.load(std::memory_order_seq_cst);
原子标志
std::atomic_flag是原子布尔类型,可以对其状态进行设置和清除。
为了简化说明,我将clear状态称为false,将set状态称为true。
1.clear方法可将其状态设置为false。
2.test_and_set方法,可以将状态设置回true,并返回先前的值。
这里,没有方法获取当前值。使用std::atomic_flag时,必须使用常量ATOMIC_FLAG_INIT将std::atomic_flag初始化为false。
ATOMIC_FLAG_INIT
std::atomic_flag需要初始化时,可以是这样:std::atomic_flag flag = ATOMIC_FLAG_INIT。
不过,不能这样进行初始化:std::atomic_flag flag(ATOMIC_FLAG_INIT)。
C++标准中的原子内部都会使用互斥锁。这些原子类型有一个is_lock_free成员函数,可用来检查原子内部是否使用了互斥锁。时下主流的微处理器架构上,都能得到“使用了互斥锁”的结果。如果想要无锁编程,那么就要使用该成员函数进行检查,确定是否使用了锁。
可以使用obj.is_lock_free(),在运行时检查原子类型的实例obj是否无锁。在C++17中,可以通过constexpr(常量)atomic::is_always_lock_free,在编译时对每个原子类型进行检查,支持该操作的所有硬件实现都无锁时,才返回true。
以下表达式永远不会失败:
if (std::atomic::is_always_lock_free) assert(std::atomic().is_lock_free());
std::atomic_flag的接口非常强大,能够构建自旋锁。自旋锁可以像使用互斥锁一样保护临界区。
自旋锁
自旋锁与互斥锁不同,它并不获取锁。而是,通过频繁地请求锁来获取临界区的访问权。不过,这会导致上下文频繁切换(从用户空间到内核空间),虽然充分使用了CPU,但也浪费了非常多的时钟周期。线程短时间阻塞时,自旋锁非常有效。通常,会将自旋锁和互斥锁组合着使用。首先,在有限的时间内使用自旋锁;如果不成功,则将线程置于等待(休眠)状态。自旋锁不应该在单处理器系统上使用。否则,自旋锁就不仅浪费了资源,而且还会减慢程序处理的速度(最好的情况),或出现死锁(最坏的情况)。
下面的自旋锁的例子,使用std::atomic_flag实现了自旋锁。
// spinLock.cpp#include <atomic>
#include <thread>
class Spinlock
{std::atomic_flag flag = ATOMIC_FLAG_INIT;
public:void lock(){while (flag.test_and_set()); //1}void unlock(){flag.clear();}
};Spinlock spin;
void workOnResource()
{spin.lock();// shared resource //2spin.unlock();
}int main()
{std::thread t(workOnResource);std::thread t2(workOnResource);t.join();t2.join();
}
线程t和t2在争夺临界区的访问权。
当线程t执行函数workOnResource时,可能会发生以下情况:
-
线程
t获取锁,若//1的标志初始值为false,则锁调用成功。这种情况下,线程t的原子操作将其设置为true。当t线程获取锁后,true将会让while陷入死循环,使得线程t2陷入了激烈的竞争当中。线程t2不能将标志设置为false,因此t2必须等待,直到线程t1执行unlock(解锁)并将标志设置为false时,才能获取锁。 -
线程
t没有得到锁时,情况1中的t2一样,需要等待。
我们将注意力放在std::atomic_flag的test_and_set成员函数上。test_and_set函数包含两个操作:读和写。原子操作就是对这两种操作进行限制。如果没有限制,线程将对共享资源同时进行读和写,根据定义,这就属于“数据竞争”,程序还会有未定义行为发生。
将自旋锁的主动等待和互斥锁的被动等待做一下比较。
自旋锁 vs互斥锁
如果函数workOnResource停顿2秒,那CPU负载会发生怎样的变化?
// spinLockSleep.cpp#include <atomic>
#include <thread>class Spinlock
{std::atomic_flag flag = ATOMIC_FLAG_INIT;
public:void lock(){while (flag.test_and_set());}void unlock(){flag.clear();}};Spinlock spin;void workOnResource()
{spin.lock();std::this_thread::sleep_for(std::chrono::milliseconds(2000));spin.unlock();
}int main()
{std::thread t(workOnResource);std::thread t2(workOnResource);t.join();t2.join();}如下图所示,四个核中每次有一个是跑满了的

我现在用互斥锁来替换自旋锁。让我们看下会发生什么。
// mutex.cpp#include <mutex>
#include <thread>std::mutex mut;void workOnResource()
{mut.lock();std::this_thread::sleep_for(std::chrono::milliseconds(5000));mut.unlock();
}int main()
{std::thread t(workOnResource);std::thread t2(workOnResource);t.join();t2.join();}
执行了好几次,但是并没有观察到任何一个核上有显著的负载。