一、简介
Gobblin是一个通用的数据抽取框架,可以从一些数据源(数据库、FTP、文件、Kafka以及自定义的数据源)抽取海量数据到Hadoop上。框架在同一个地方管理所有不同数据源的元数据,同时具备可扩展、容错、数据质量保证等特性,是一个高效的数据抽取框架。
二、Gobblin架构
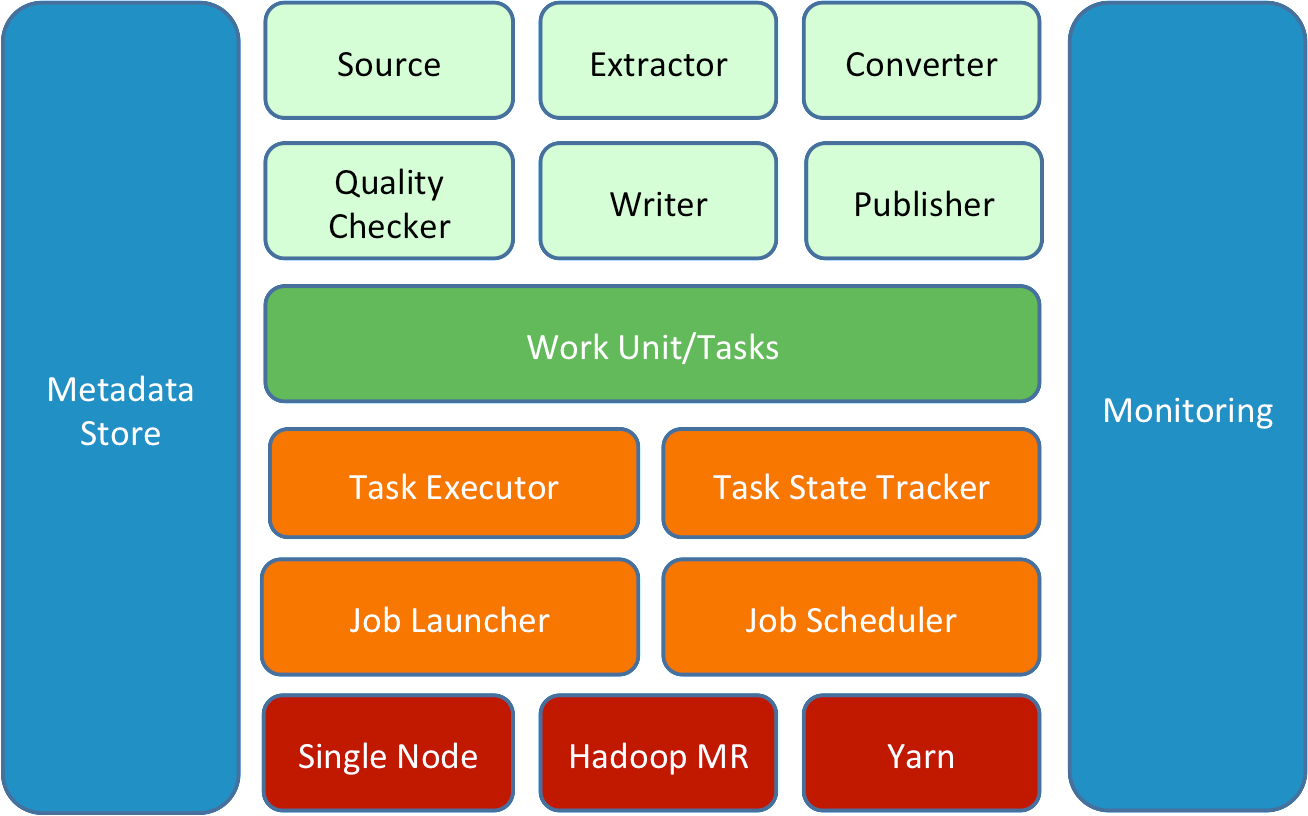
(一)框架概述
一个Gobblin任务由图中浅绿色部分组件构成。每个组件都提供了相应接口和简单的实现,所有组件通过配置文件进行组合,用户也可以结合自己的需求编写自定义组件。
Job被分割成若干个Work Unit,每一个Task对应一个Work Unit,负责指定部分数据的抽取。
所有的Task运行于Gobblin的部署环境上,部署环境由橙色部分的执行器及任务管理器组成。
Gobblin的部署方式有三种:Single Node、Hadoop MR、Yarn,其中Yarn模式是指独立运行于Yarn之上的Application,而非MR,目前只是提出,尚未开发出。
(二)job执行流程

1、Job开始时,首先获取一把任务锁,目的是防止下个相同的调度作业在Job尚未完成就开始执行,此步可选。
2、实例化Source,Source将数据抽取任务分解为一系列Work Unit,每个Unit对应一部分数据。同时,Source为每一个Unit指定Extractor用于从数据源获取数据。
3、Job为每一个Work Unit创建一个Task实际执行任务。
4、启动执行所创建的Task
5、发布Task抽取到的数据
6、持久化任务状态信息
7、清除临时文件
8、释放任务锁
(三)组件详解
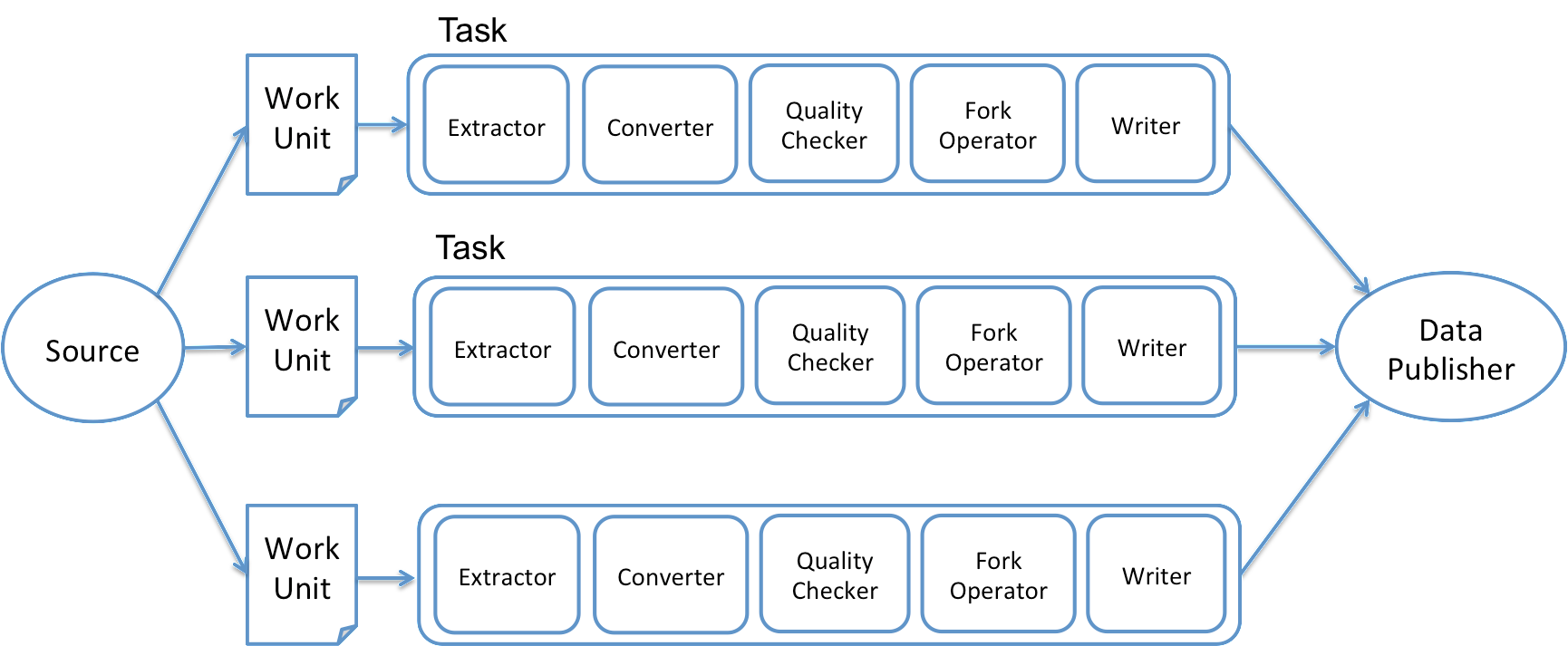
1、Source&Extractor
Source在数据源和Gobblin之间起到适配器的作用,在工作开始阶段将任务划分为Work Unit,同时为其创建Extractor。Extractor负责数据的实际读取工作。Gobblin内嵌了多种Source及Extractor适用于多种数据源。
2、Converter
Converter将数据类型转化为所需要的,如将Avro转为Byte[],CSV转JSON等等。此组件为可选,亦可多选,多选时需注意排列顺序,前一个Converter的输出将作为下一个Convertor的输入。
3、QualityChecker
Quality Checker用于保证数据质量,有两种类型,一种是基于Record的检查,决定Record是否可以进入下一个任务阶段,另一种是对Task输出的检查,决定Task输出是否可以Commit给Publisher。此组件为可选亦可多选。
4、ForkOperator
Fork Operator主要用于数据需要被写入多个不同的存储器或者以不同的格式写入同一个存储器的情况。它将数据分入不同的数据流,每一个数据流都由相应的Writer写入不同存储器或不同格式。此组件可选。
5、Writer
Writer按照配置将数据以指定格式写入指定位置作为Task的输出。
6、Publisher
发布数据,通常是将数据从Task输出目录一定到配置文件指定的data.publisher.final.dir
以上组件都可以自定义编写,同时进行自由组合,所以Gobblin具有较高的可扩展性和通用性。
(四)任务管理与调度
1、任务状态管理
Gobblin Job通常是一个周期执行的增量抽取数据的任务,即下一次执行从上一次执行结束的位置开始。实现这样的增量查询,需要Gobblin将任务执行状态持久化。Gobblin通过维持一个state-store来持久化任务状态,每一次Job运行结束后,都会将状态信息写入state-store以供下一次运行使用。
2、任务调度
Gobblin通常是周期性调度执行的,他可以由Azkaban、Oozie、Crontab等调度器调度执行,Gobblin还内嵌了一个基于Quartz的调度器。
(五)部署 Deployment Architecture
Standalone Architecture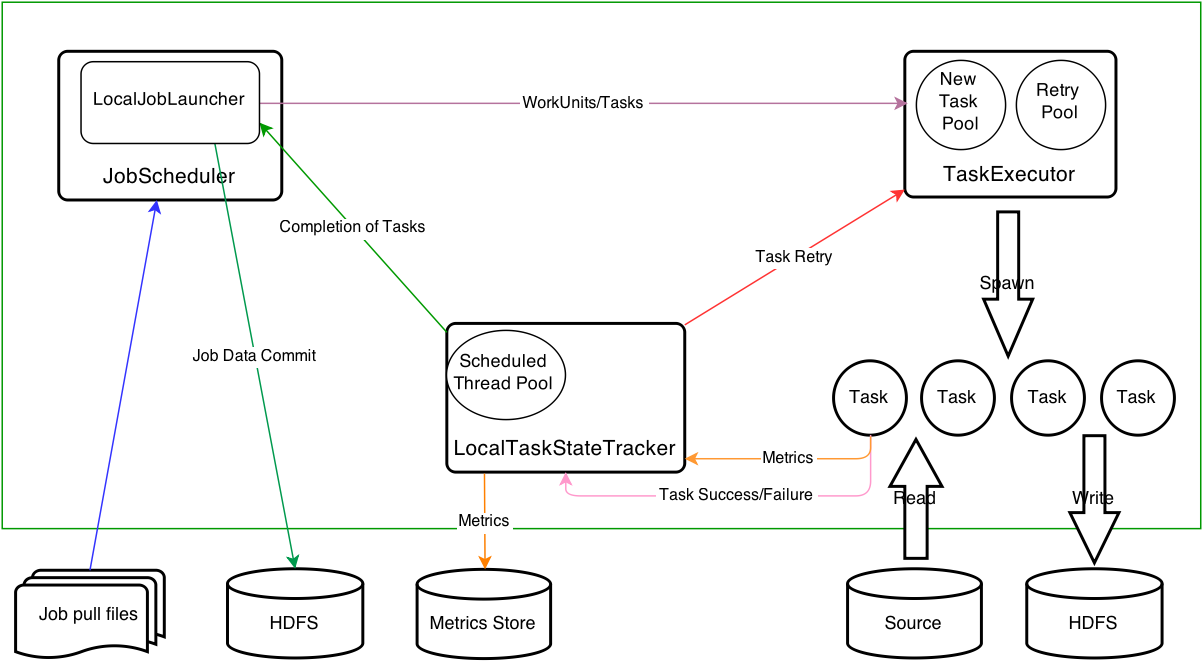
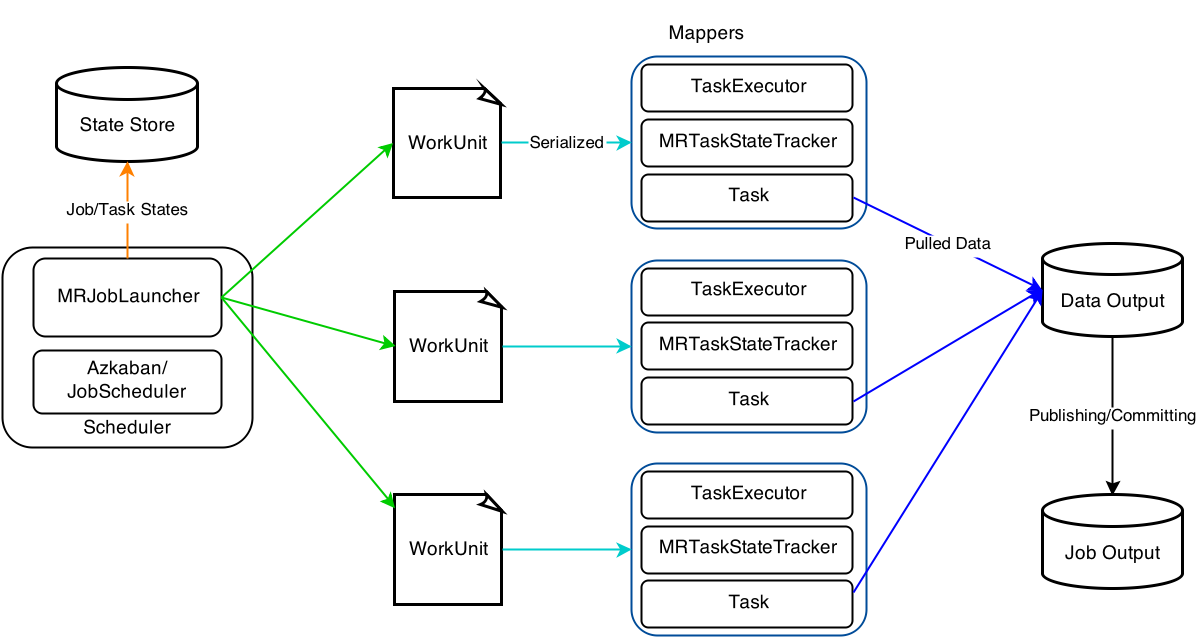
Hadoop MapReduce Architecture
Gobblin on YARN
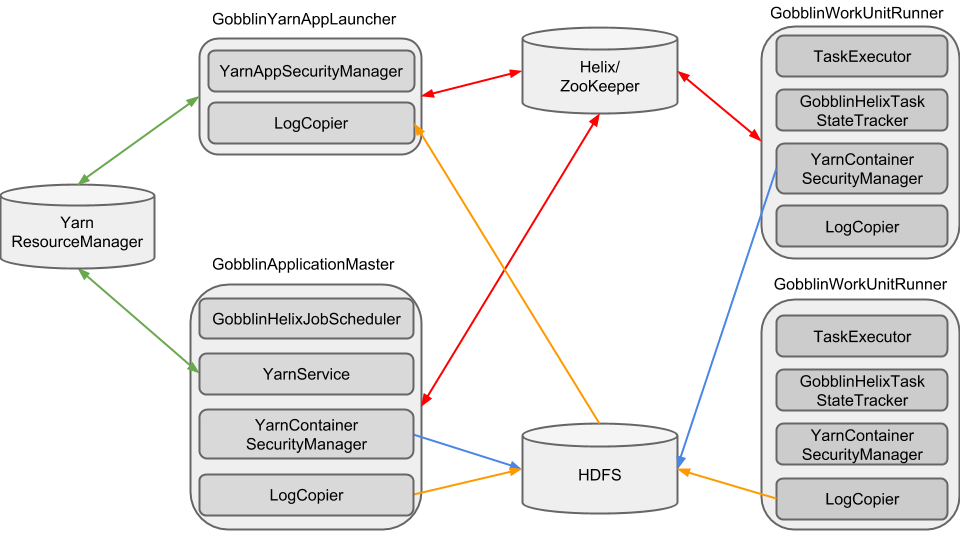
三、Gobblin的优势
(一)可扩展
Task的组成方式灵活,组件都可以自定义编写,使得Gobblin可以应对几乎任何形式的数据源,并将所有数据抽取任务统一管理。
(二)可以部署在Yarn上
Gobblin Job可以以MapReduce的形式直接运行在Yarn上,在HDFS读写上具有更高效率。
转:https://blog.csdn.net/a153095800/article/details/70173169