优化数据模型和算法,合理分区和存储,使用分布式计算框架,提高并发度和处理速度,降低延迟。
了解MaxCompute的基本概念和架构
1、MaxCompute是阿里巴巴推出的一款大数据计算服务,提供了大规模数据仓库解决方案。
2、基于分布式计算框架,可以处理PB级别的数据。
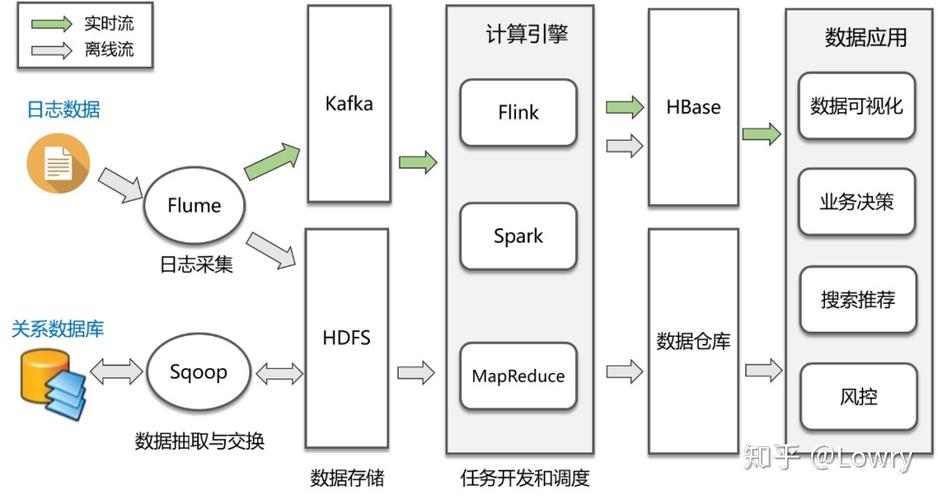
3、支持多种计算模型,如批处理、流式计算、交互式分析等。
4、提供丰富的数据开发和管理功能,包括数据导入、数据清洗、数据分析等。
选择合适的计算资源
1、根据业务需求选择合适的项目类型,如公共项目、专有项目等。
2、选择合适的计算资源规格,如CPU、内存、磁盘等。
3、根据任务并发度和执行时间选择合适的节点数量。
4、合理分配资源,避免资源浪费和性能瓶颈。
优化数据处理流程
1、减少数据量:通过数据采样、数据清洗等方式减少数据量,提高计算效率。

2、优化数据分区:合理划分数据分区,避免数据倾斜,提高并行度。
3、使用合适的压缩算法:根据数据特点选择合适的压缩算法,降低存储成本和计算成本。
4、使用缓存:对于重复计算的中间结果,可以使用缓存机制提高计算效率。
选择合适的计算模型和算法
1、根据业务需求选择合适的计算模型,如批处理、流式计算等。
2、选择合适的算法,如排序、聚合等,提高计算效率。
3、使用MapReduce编程模型简化计算逻辑。
4、使用SQL进行数据分析,提高开发效率。

监控和调优MaxCompute任务
1、使用MaxCompute提供的监控工具,如作业监控、资源监控等,实时了解任务运行状态。
2、根据监控数据调整任务参数,如并发度、节点数量等,优化任务性能。
3、分析任务日志,查找性能瓶颈和故障原因。
4、定期对MaxCompute集群进行维护和优化,确保集群稳定运行。
培训和学习MaxCompute相关知识
1、参加MaxCompute官方培训课程,了解MaxCompute的基本概念和操作方法。
2、阅读MaxCompute官方文档,深入了解MaxCompute的功能和使用方法。
3、参与社区讨论,学习其他用户的经验和技术分享。
4、不断实践和归纳,提高自己在MaxCompute领域的技能水平。